Spring Cloud 作為構(gòu)建分布式微服務(wù)系統(tǒng)的核心框架,是Java開發(fā)者面試中的熱點(diǎn)話題。本文將圍繞常見的面試問題,系統(tǒng)性地解析其核心概念、關(guān)鍵組件及實(shí)踐要點(diǎn)。
一、Spring Cloud 五大核心組件
Spring Cloud 并非單一技術(shù),而是一個(gè)由多個(gè)獨(dú)立項(xiàng)目組成的生態(tài)系統(tǒng),旨在提供微服務(wù)架構(gòu)的綜合性解決方案。通常所說的“五大組件”是一個(gè)概括性說法,指代其最核心與常用的模塊:
- 服務(wù)注冊(cè)與發(fā)現(xiàn) (Eureka / Nacos):微服務(wù)實(shí)例啟動(dòng)后向注冊(cè)中心注冊(cè)自己的信息(如IP、端口、服務(wù)名),其他服務(wù)通過查詢注冊(cè)中心來發(fā)現(xiàn)并調(diào)用目標(biāo)服務(wù)。這是實(shí)現(xiàn)服務(wù)間動(dòng)態(tài)通信的基礎(chǔ)。
- 客戶端負(fù)載均衡 (Ribbon / Spring Cloud LoadBalancer):在服務(wù)消費(fèi)者端實(shí)現(xiàn)負(fù)載均衡,能夠?qū)淖?cè)中心獲取的服務(wù)實(shí)例列表,按照特定策略(如輪詢、隨機(jī)、權(quán)重)選擇一個(gè)實(shí)例進(jìn)行調(diào)用。
- 服務(wù)容錯(cuò)與熔斷 (Hystrix / Resilience4j / Sentinel):當(dāng)某個(gè)服務(wù)實(shí)例故障或響應(yīng)過慢時(shí),防止故障蔓延導(dǎo)致整個(gè)系統(tǒng)崩潰。通過熔斷器快速失敗、服務(wù)降級(jí)返回托底數(shù)據(jù)等手段,保障系統(tǒng)的高可用性。
- API網(wǎng)關(guān) (Zuul / Spring Cloud Gateway):作為系統(tǒng)對(duì)外的統(tǒng)一入口,負(fù)責(zé)請(qǐng)求路由、過濾、認(rèn)證、限流、監(jiān)控等跨橫切面功能。它將內(nèi)部復(fù)雜的微服務(wù)結(jié)構(gòu)對(duì)客戶端透明化。
- 分布式配置中心 (Spring Cloud Config / Nacos):集中管理所有微服務(wù)環(huán)境的配置文件,支持動(dòng)態(tài)刷新,無需重啟服務(wù)即可實(shí)現(xiàn)配置變更,極大地提升了運(yùn)維效率。
二、Nacos 與 Eureka 的區(qū)別
Eureka 和 Nacos 都是優(yōu)秀的服務(wù)注冊(cè)與發(fā)現(xiàn)組件,但 Nacos 功能更為全面。
- 功能定位:Eureka 專注于服務(wù)注冊(cè)與發(fā)現(xiàn);Nacos 則集成了服務(wù)注冊(cè)發(fā)現(xiàn)、配置管理、服務(wù)元數(shù)據(jù)管理,是“注冊(cè)中心 + 配置中心”的一體化解決方案。
- 健康檢查:Eureka 通過客戶端心跳來判定服務(wù)是否可用;Nacos 支持更豐富的健康檢查模式,如TCP/HTTP探測(cè)、以及基于集群的的健康檢查。
- 一致性協(xié)議:Eureka 采用AP設(shè)計(jì),在集群間數(shù)據(jù)復(fù)制時(shí)優(yōu)先保證可用性,允許短暫的數(shù)據(jù)不一致;Nacos 支持AP和CP兩種模式,可根據(jù)場(chǎng)景(如服務(wù)發(fā)現(xiàn)用AP,配置管理用CP)靈活切換,一致性更強(qiáng)。
- 易用性與生態(tài):Nacos 提供友好的控制臺(tái),支持服務(wù)的權(quán)重、灰度等更細(xì)粒度的管理,且與 Spring Cloud Alibaba 生態(tài)集成更緊密,是目前國(guó)內(nèi)更為主流的選擇。
三、服務(wù)雪崩、服務(wù)熔斷與服務(wù)降級(jí)
這是微服務(wù)容錯(cuò)體系中的核心概念。
- 服務(wù)雪崩:指由于某個(gè)基礎(chǔ)服務(wù)故障,導(dǎo)致其上游依賴服務(wù)發(fā)生級(jí)聯(lián)故障,最終像雪崩一樣擴(kuò)散至整個(gè)系統(tǒng)的現(xiàn)象。根本原因通常是:服務(wù)間同步調(diào)用、沒有緩存、沒有容錯(cuò)機(jī)制。
- 服務(wù)熔斷:一種主動(dòng)的防護(hù)機(jī)制。當(dāng)某個(gè)目標(biāo)服務(wù)的調(diào)用失敗率或慢請(qǐng)求比例達(dá)到預(yù)設(shè)閾值時(shí),熔斷器會(huì)“打開”,在一段時(shí)間內(nèi)直接拒絕所有對(duì)該服務(wù)的請(qǐng)求,快速返回失敗,避免資源被持續(xù)占用。經(jīng)過熔斷時(shí)間窗后,會(huì)進(jìn)入“半開”狀態(tài)試探性放行部分請(qǐng)求,若成功則關(guān)閉熔斷,恢復(fù)調(diào)用。
- 服務(wù)降級(jí):當(dāng)系統(tǒng)整體負(fù)載過高或某個(gè)非核心服務(wù)不可用時(shí),為了保證核心業(yè)務(wù)的可用性,有計(jì)劃地暫時(shí)“犧牲”部分非核心功能或提供簡(jiǎn)化版服務(wù)。例如,在商品詳情頁,若評(píng)論服務(wù)不可用,則隱藏評(píng)論模塊,或顯示預(yù)設(shè)的靜態(tài)提示,而不是讓整個(gè)頁面報(bào)錯(cuò)。
關(guān)系:熔斷是觸發(fā)降級(jí)的一種常見手段。當(dāng)熔斷器打開后,通常會(huì)執(zhí)行預(yù)定義的服務(wù)降級(jí)邏輯,返回一個(gè)兜底響應(yīng)(fallback)。
四、微服務(wù)監(jiān)控
完備的監(jiān)控是微服務(wù)穩(wěn)定運(yùn)行的“眼睛”。主要包括:
- 指標(biāo)收集 (Metrics):使用 Micrometer 等工具收集每個(gè)服務(wù)的JVM性能指標(biāo)(GC、內(nèi)存)、HTTP請(qǐng)求量、響應(yīng)時(shí)間、錯(cuò)誤率等。
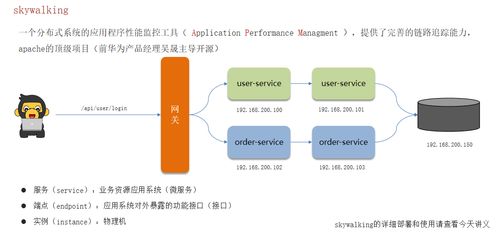
- 鏈路追蹤 (Tracing):使用 Sleuth 集成 Zipkin 或 SkyWalking,為一次分布式請(qǐng)求提供完整的調(diào)用鏈路視圖,便于定位性能瓶頸和故障點(diǎn)。
- 日志聚合 (Logging):使用 ELK(Elasticsearch, Logstash, Kibana)或 EFK 棧,將分散在各個(gè)節(jié)點(diǎn)上的日志集中收集、存儲(chǔ)與可視化分析。
- 健康檢查與告警:通過 Spring Boot Actuator 暴露健康端點(diǎn),結(jié)合 Prometheus 和 Grafana 進(jìn)行指標(biāo)采集、儀表盤展示和閾值告警。
五、項(xiàng)目策劃與微服務(wù)化考量
在項(xiàng)目初期決定是否采用微服務(wù)架構(gòu)時(shí),需進(jìn)行審慎策劃:
- 評(píng)估必要性:微服務(wù)帶來了獨(dú)立部署、技術(shù)異構(gòu)、彈性擴(kuò)展等好處,但也引入了分布式事務(wù)、測(cè)試、部署、運(yùn)維的復(fù)雜性。切忌為了“微服務(wù)”而微服務(wù),適合復(fù)雜度高、團(tuán)隊(duì)規(guī)模大、需快速迭代的大型系統(tǒng)。
- 服務(wù)拆分原則:遵循單一職責(zé)、松耦合高內(nèi)聚的原則。常用拆分維度包括業(yè)務(wù)領(lǐng)域(DDD)、功能模塊、數(shù)據(jù)獨(dú)立性等。
- 基礎(chǔ)設(shè)施先行:確保自動(dòng)化CI/CD流水線、容器化(如Docker/K8s)、監(jiān)控告警體系、配置中心、日志中心等基礎(chǔ)設(shè)施就緒,這是微服務(wù)成功落地的技術(shù)保障。
- 團(tuán)隊(duì)與流程適配:微服務(wù)要求團(tuán)隊(duì)組織結(jié)構(gòu)向“康威定律”靠攏,即小團(tuán)隊(duì)負(fù)責(zé)完整的垂直業(yè)務(wù)線(全功能團(tuán)隊(duì))。開發(fā)流程需支持服務(wù)的獨(dú)立開發(fā)、測(cè)試和部署。
綜上,掌握 Spring Cloud 不僅是了解其組件用法,更要深入理解其背后的分布式系統(tǒng)設(shè)計(jì)思想。在面試中,結(jié)合自身項(xiàng)目經(jīng)驗(yàn),清晰地闡述這些概念的聯(lián)系與實(shí)踐,將能顯著提升表現(xiàn)。